Welcome to guanjunjian's Blog!
-
「十八」数据包的转发 dev_forward_skb源码分析
基于内核4.14.5
本文是study17. veth_xmit分析的后续分析
1. 代码调用过程
发送端(veth):
|--->dev_forward_skb() |--->__dev_forward_skb() | |--->____dev_forward_skb() | | |--->if() // 判断是否可转发 | | |--->skb_scrub_packet() //清除skb可能破坏命名空间独立性的信息 | | | |--->skb_orphan() | | | |--->skb->destructor() //调用skb的destructor | | | |--->skb->sk = NULL //将skb的sk字段设为NULL,这里classid就被丢弃了 | | |--->skb->priority = 0 | |--->if (likely(!ret)) // 如果____dev_forward_skb执行正确 | |--->skb->protocol = eth_type_trans() | |--->skb_postpull_rcsum() |--->netif_rx_internal() //如果__dev_forward_skb执行正确 |--->enqueue_to_backlog() //将数据包添加到per-cpu的接收队列中 |--->__skb_queue_tail() //将skb保存到input_pkt_queue队列中 |--->____napi_schedule() //唤醒软中断 |--->list_add_tail() //将该设备添加到softnet_data的poll_list队列中 |--->__raise_softirq_irqoff() //唤醒软中断,调用对应的设备(veth peer)来收包
-
「十七」Linux虚拟网络设备veth veth_xmit源码分析
基于内核4.14.5
目的是了解veth的数据包转发流程,了解classid是在何处被丢弃的
1. 使用方法
//使用veth //1.创建两块虚拟网卡veth1、veth2,然后点对点连接,此后两块网卡的数据会互相发送到对方 $ ip link add veth1 type veth peer name veth2 //2.创建网络命名空间t1 $ ip netns add t1 //3.将veth0加入t1,此时veth1便看不到了,因为被加入到其他命名空间中了 $ ip link set veth1 netns t1 //4.配置veth1的ip地址 $ ip netns exec t1 ifconfig veth1 192.168.1.200/24 //5.设置t1网络的默认路由 $ ip netns exec t1 route add default gw 192.168.1.1 //6.此时将veth2加入本地网桥中,便可以实现veth1在t1中访问外部网络了,过程略,可参考docker中的网络配置步骤
-
「十六」Cgourp子系统net_cls cls_cgroup_classify源码分析
了解该函数的目的是根据net_next中提出:tc无法捕捉veth转发后的数据包,是因为classid被清空导致的
所以这篇博客的目的是了解veth转发的过程,并发现classid存储位置
基于内核4.14.5
1.cls_cgroup_classify
cls_cgroup_classify从该函数进入,主要想了解classid获取的过程,代码如下:
static int cls_cgroup_classify(struct sk_buff *skb, const struct tcf_proto *tp, struct tcf_result *res) { struct cls_cgroup_head *head = rcu_dereference_bh(tp->root); u32 classid = task_get_classid(skb); if (!classid) return -1; if (!tcf_em_tree_match(skb, &head->ematches, NULL)) return -1; res->classid = classid; res->class = 0; return tcf_exts_exec(skb, &head->exts, res); }
-
「十五」《再谈Docker容器单机网络:利用iptables trace和ebtables log》读后整理
本文对Tony Bai博文再谈Docker容器单机网络:利用iptables trace和ebtables log的内容整理,对其中一些不懂的知识点补充,并增加图片了解。
文中图片和日志均出自该博文。
1.简介
本文利用iptables和etables的日志,分析单机容器网络在
Container to Container、Local Process to Container和Container to External三种场景下的数据包行走路径。简易的容器网络拓扑如图1.:
图1.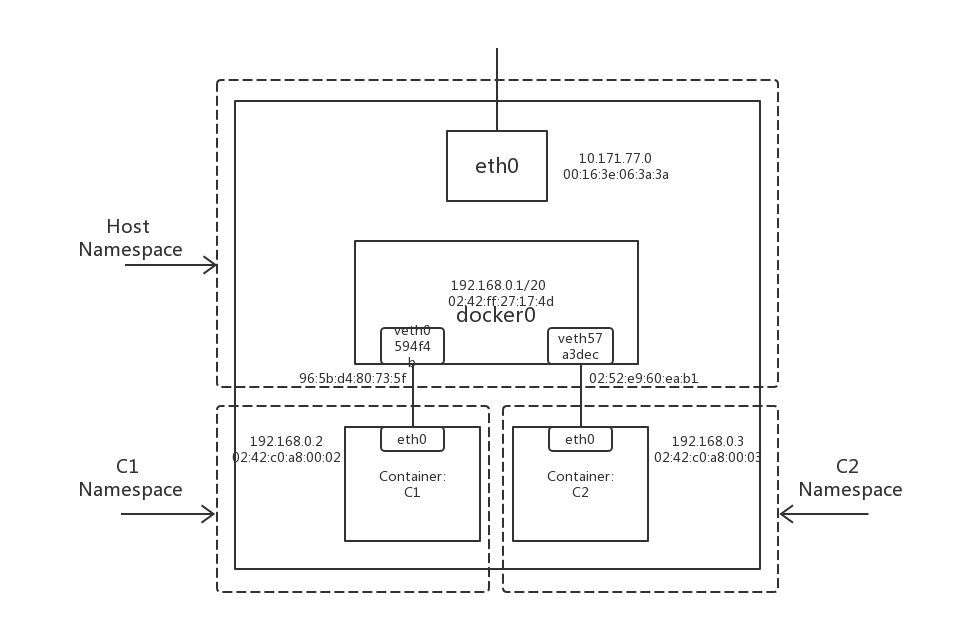
文章基于netfilter数据流图2.来做数据路径分析。
-
「十四」利用Cgroup限制网络带宽
本文是对CONTROLLING NETWORK RESOURCES USING CONTROL GROUPS的翻译。
cgroup net_cls与tc htb结合使用,达到对cgroup网络资源限制的目的。
简介
Control Groups为聚合/分区task集提供了一种机制,而且这些task的子task也会进入相同的层级的cgroup。cgroup的网络子系统可以提供资源控制从而达到调度资源或实施每个cgroup限制的目的。
这篇文档将解释cgroup在Linux数据包调度环境下的架构,并且将给出可亲手实践的例子来解释如何使用它。
架构
使用cgroup控制网络资源的基本思想是将cgroup与已经存在的能提供分类和调度网络数据包功能的网络数据包分类器和调度框架连接起来。
为了达到这一的目的,创建了一种新的cgroup子系统net_cls,该子系统可以让cgroup可以分辨数据包流量是从哪个cgroup中流出的。这是通过给cgroup分配一个classid实现的,classid可以被数据包分类器cls_cgroup使用,从而将数据包过滤到classid匹配的流量类型中,如下图1.所示。
图1:
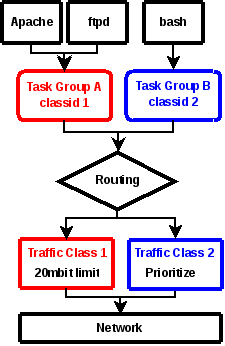
-
「十三」Cgroup子系统 net_prio文档
Documentation/cgroups/net_prio.txt的翻译。
基于内核4.3,文档生成时间 2015-11-02 12:44 EST。
这个子系统提供了一种动态控制每个网卡流量优先级的功能
Network priority cgroup
Network priority cgroup提供了一个允许管理者动态设置由应用产生的网络流量优先级的接口。
表面上,一个应用可以使用socket的选项SO_PRIORITY来设置它产生的流量的优先级,然而,这并非总是可能的,因为:
- 1) 应用程序可能没有在代码中设置这个值
- 2) 应用流量的优先级常常是特定地点的管理决定(site-specific administrative decision)而不是由应用程序自身定义的
该cgroup运行管理者将一个进程分配到一个cgroup中,在这个cgroup中定义了在指定网络接口中,外出流量(egress traffic)的优先级。Network priority group可以在第一次挂载cgroup文件系统的时候创建。
# mount -t cgroup -onet_prio none /sys/fs/cgroup/net_prio